小明:老师,上次您讲了MD5算法。用它生成的信息摘要,真的可以被破解吗?
老师:有很多种方法可以破解,不过需要明确一点,这里所谓的破解,并非把摘要还原成原文。为什么呢?因为固定128位的摘要是有穷的,而原文数量是无穷的,每一个摘要都可以由若干个原文通过Hash得到。
小明:如果是这样的话,网上所说的MD5破解到底是怎么回事呢?
老师:对于MD5的破解,实际上都属于【碰撞】。比如原文A通过MD5可以生成摘要M,我们并不需要把X还原成A,只需要找到原文B,生成同样的摘要M即可。
设MD5的哈希函数是H(X),那么:
H(A) = M
H(B) = M
任意一个B即为破解结果。
B有可能等于A,也可能不等于A。
用一个形象的说法,A和B的MD5结果“殊途同归”。
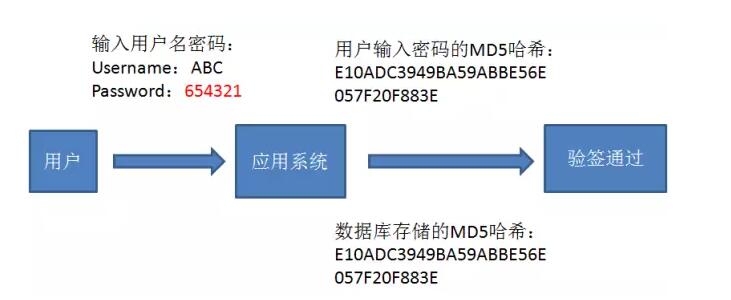
MD5碰撞通常用于登陆密码的破解。应用系统的数据库中存储的用户密码通常都是原密码的MD5哈希值,每当用户登录时,验签过程如下:

如果我们得到了用户ABC的密码哈希值E10ADC3949BA59ABBE56E057F20F883E,并不需要还原出原密码123456,只需要“碰撞”出另一个原文654321(只是举例)即可。登录时,完全可以使用654321作为登陆密码,欺骗过应用系统的验签。
小明:那么,具体如何来实现MD5摘要的碰撞呢?
老师:MD5碰撞的方法有很多,主要包括暴力枚举法、字典法、彩虹表法等等。
暴力枚举法:
老师:暴力枚举法顾名思义,就是简单粗暴地枚举出所有原文,并计算出它们的哈希值,看看哪个哈希值和给定的信息摘要一致。这种方法虽然简单,但是时间复杂度极高。想象一下,仅仅长度8位的密码就有多少种排列组合的可能性?
小明:只考虑大小写字母和数字,每一位有62种可能,那么8位密码的排列组合就是62的8次方,218340105584800,约等于二百万亿!
老师:是的,这样的数据量如果使用普通的单机来破解,恐怕头发白了也破解不完。不过,我们也可以做一些取巧,优先尝试生日和有意义的单词,这样就可以把穷举范围缩小很多。
字典法:
老师:如果说暴力枚举法是ongoing时间换空间,那么字典法则是用空间换时间。黑客利用一个巨大的字典,存储尽可能多的原文和对应的哈希值。每次用给定的信息摘要查找字典,即可快速找到碰撞的结果。

不过,这样做虽然每次破解速度很快,但是生成字典需要巨大的空间。仍然以8位密码举例,需要多大空间呢?
小明:刚才计算过有218340105584800种可能性,每一对映射占192(128+64)bit。那么大约需要4.65PB的存储空间。
老师:没错,这样做的存储成本实在太大了。当然,我们同样可以取巧,优先存储那些常用的密码及其摘要。
小明:那么,有没有什么方法可以做到时间和空间的均衡呢?
老师:有一种方法可以,那就是下面我要介绍的【彩虹表发】。
彩虹表法:
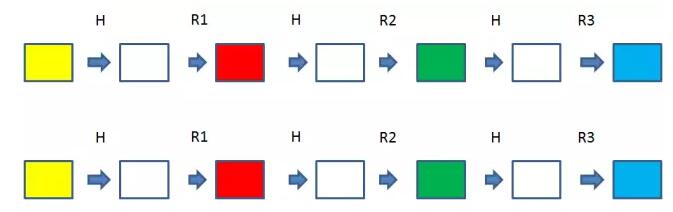
老师:彩虹表法可以说是对字典法的优化,它采用了一种有趣的数据结构:【彩虹表】。在学习彩虹表之前,我们先来了解两个基本函数:H(X)和R(X)。
H(X):生成信息摘要的哈希函数,比如MD5,比如SHA256。
R(X):从信息摘要转换成另一个字符串的衰减函数(Reduce)。其中R(X)的定义域是H(X)的值域,R(X)的值域是H(X)的定义域。但要注意的是,R(X)并非H(X)的反函数。
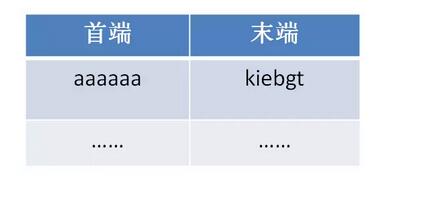
通过交替运算H和R若干次,可以形成一个原文和哈希值的链条。假设原文是aaaaaa,哈希值长度32bit,那么哈希链表就是下面的样子:

这个链条有多长呢?假设H(X)和R(X)的交替重复K次,那么链条长度就是2K+1。同时,我们只需把链表的首段和末端存入哈希表中:
小明:这什么跟什么啊,衰减函数和哈希链条,到底是干什么用的?
老师:别急,我们来演示一次破解过程,你就明白它们的意义了。
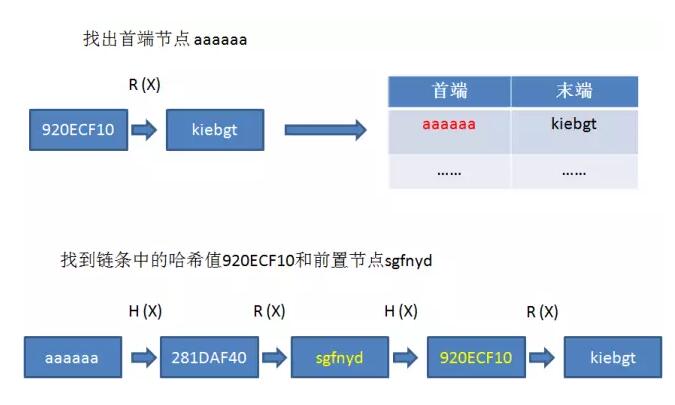
给定信息摘要:920ECF10
如何得到原文呢?只需进行R(X)运算:
R(920ECF10)= kiebgt
查询哈希表可以找到末端kiebgt对应的首端是aaaaaa,因此摘要920ECF10的原文“极有可能”在aaaaaa到kiebgt的这个链条当中。
接下来从aaaaaa开始,重新交替运算R(X)与H(X),看一看摘要值920ECF10是否是其中一次H(X)的结果。从链条看来,答案是肯定的,因此920ECF10的原文就是920ECF10的前置节点sgfnyd。
需要补充的是,如果给定的摘要值经过一次R(X)运算,结果在哈希表中找不到,可以继续交替H(X)R(X)直到第K次为止。
简单来说,哈希链表代表了一组映射关系,其中每组包含K对映射,但只需要存储链条首位两个字符串。假设K=10,那么存储空间只有全量字典的十分之一,代价则是破解一个摘要的运算次数也提高了十倍。这就是时间和空间的取舍。虽然做了取舍,但是哈希链条存在一个致命的缺陷:R(X)函数的可靠性。虽然我们尽量把R(X)设计成结果均匀分布的函数,但是再完美的函数也难免会有碰撞的情况,比如下面这样:
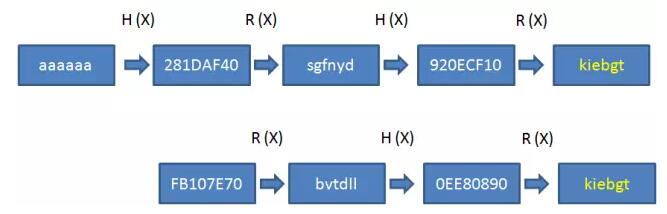
给定信息摘要:FB107E70
经过多次R(X),H(X)运算,得到结果kiebgt
通过哈希表查找末端kiebgt,可以找出首端aaaaaa
但是,FB107E70并不在aaaaaa到kiebgt的哈希链条当中,这就是R(X)的碰撞造成的。
这个问题看似没什么影响,既然找不到就重新生成一组首尾映射即可。但是想象一下,当K值较大的时候,哈希链很长,一旦两条不同的哈希链在某个节点出现碰撞,后面所有的明文和哈希值全都变成了一毛一样的值。
这样造成的后果就是冗余存储。原本两条哈希链可以存储 2K个映射,由于重复,真正存储的映射数量不足2K。
这个时候,我们设计了彩虹表。彩虹表对哈希链进行了改进,把原先的R(X)的函数改进成从R1(X)到Rk(X)一共K个衰减函数。这样一来虽然也可能发生碰撞,但是碰撞只会发生在同一级运算,如R1和R1碰撞,R3和R3碰撞,大大减小了存储重复的几率。
小明:好复杂,听的头都晕了。那想要破解MD5算法,有没有比彩虹表更厉害的方法呢?
老师:还真有。
2004年,王小云教授提出了非常高效的MD5碰撞方法。
2009年,冯登国、谢涛利用差分攻击,将MD5的碰撞算法复杂度进一步降低。
有兴趣的小伙伴可以通过资料进行更深入的学习。
几点补充:
对于单机来说,暴力枚举法的时间成本很高,字典法的空间成本很高。但是利用分布式计算和分布式存储,仍然可以有效破解MD5算法。因此这两种方法同样被黑客们广泛使用。

